

Researchers from Aural Analytics, Inc., Arizona State University, and the University of Wisconsin School of Medicine and Public Health presented new research connecting speech to dementia at the Alzheimer’s Association International Conference (AAIC) on July 26-30, 2021.
The research provides validation data for a set of automatic algorithms that quantify cognitive impairment from speech recordings, and deepens our understanding of the degradation of communicative function over the course of Alzheimer’s disease.
Below, we provide a summary of the three studies that we presented at the conference. These studies demonstrated that:
- Automatically-extracted language features were valid, with performance comparable to those measured manually by trained coders
- Automatically-extracted language features were clinically-relevant biomarkers for the diagnosis of MCI and Alzheimer’s disease
- A broad spectrum of language measures was similar whether collected in a supervised, in-clinic environment, or in a remote, at-home environment
This collaborative research project is in line with our common mission to develop and validate sensitive metrics that tap speech as a biomarker of cognitive function. Key to accomplishing this mission is the validation of automated metrics that can be effectively and efficiently deployed at scale. This work presented at AAIC represents a major step forward toward this goal.
Large-Scale Cross-Sectional and Longitudinal Validation of a Digital Speech-Based Measure of Cognition
Our first study introduced an automated measure of cognition that could be extracted from a recording of a picture description. The measure was previously developed on an extant speech database. We validated this measure on a different large-scale dataset by showing that it was accurate, clinically relevant, and tracked longitudinal change. The automated measure, called Semantic Relevance (SemR), essentially characterizes an individual’s ability to interpret and describe a complex picture. To validate this metric, we compared the automatically calculated values relative to several clinical endpoints on a set of descriptions of a picture that is part of the Boston Diagnostic Aphasia Examination: The Cookie Theft Picture. Descriptions were collected every ~2 years from participants with a range of cognitive functioning.
| Our first goal was to show that this measure (SemR) was accurate relative to a gold standard: hand measurements of the transcripts, laboriously completed by trained coders. Results showed that the manually-annotated and algorithmically-calculated SemR scores were highly correlated (r = 0.85). | 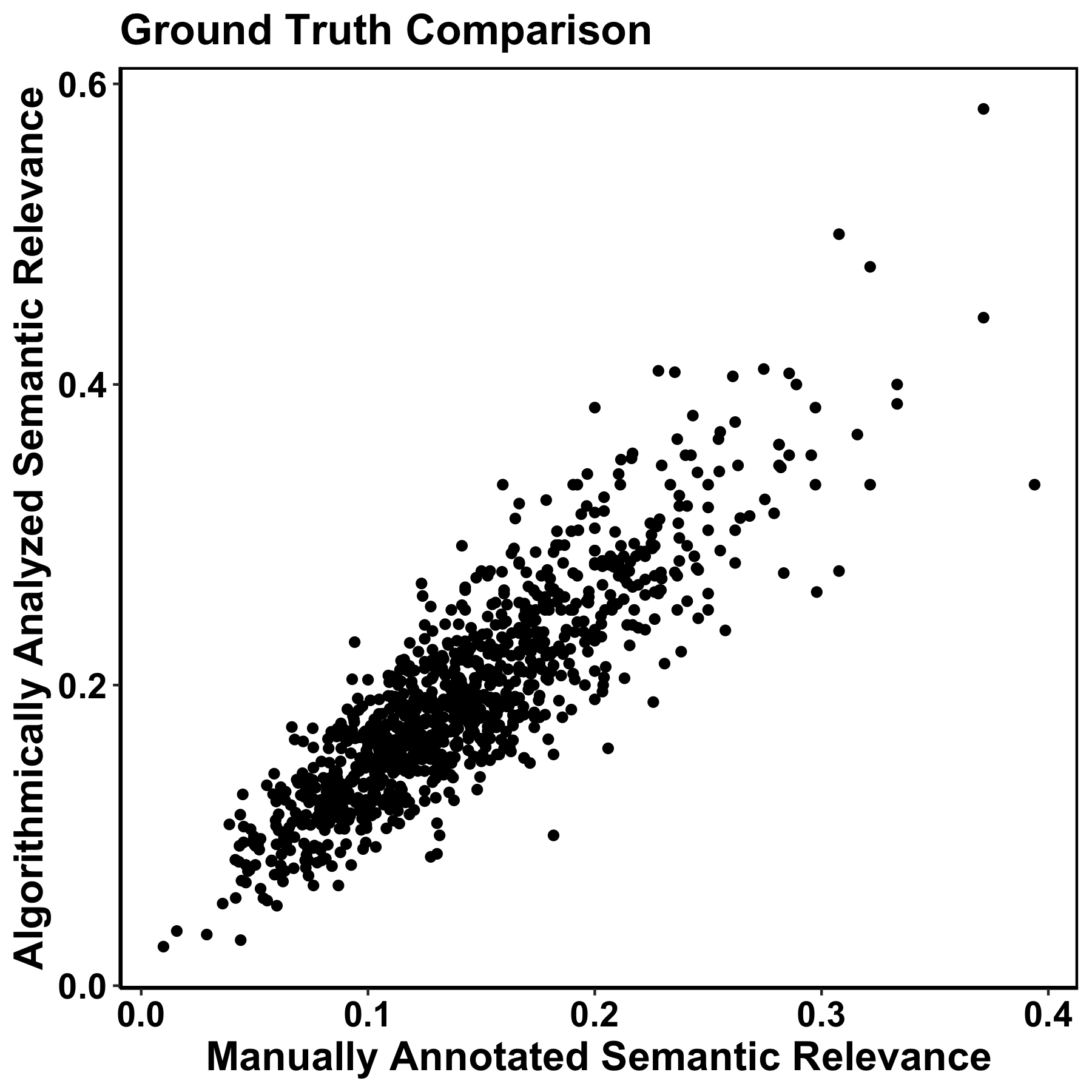 |
| Then we showed that SemR correlated significantly with the Mini Mental State Exam (MMSE), a test battery commonly used in the assessment of cognitive function. The plot to the right shows the cross-sectional correspondence between a patient’s SemR, as computed by our automated measure, and their MMSE score. As expected, semantic relevance and cognition were positively related, such that participants with lower MMSE scores had lower SemR values. | 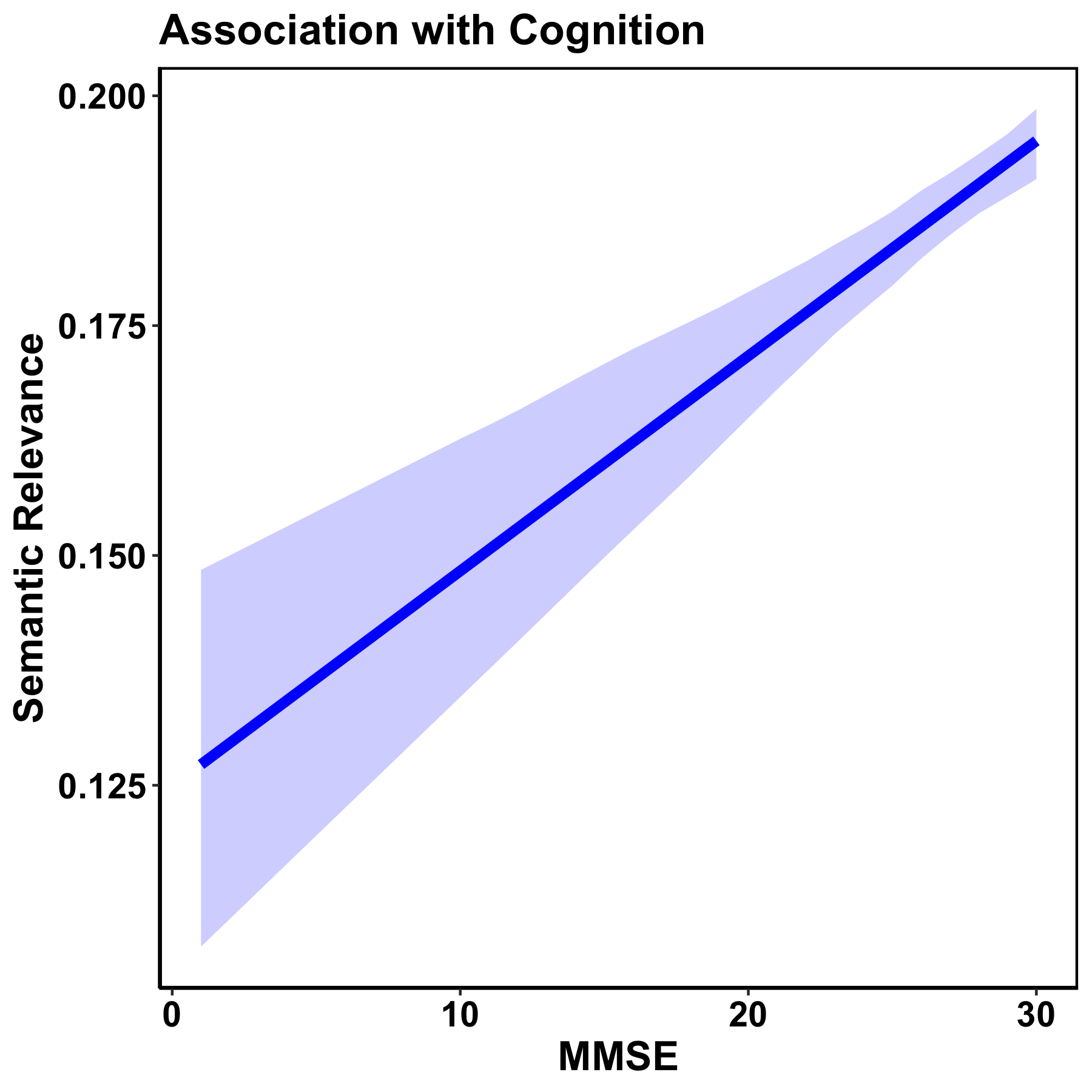 |
| Finally, we showed that as participants aged, their SemR scores declined. As expected, the speed of decline was faster in the cognitively impaired groups than in the group with normal cognition. | 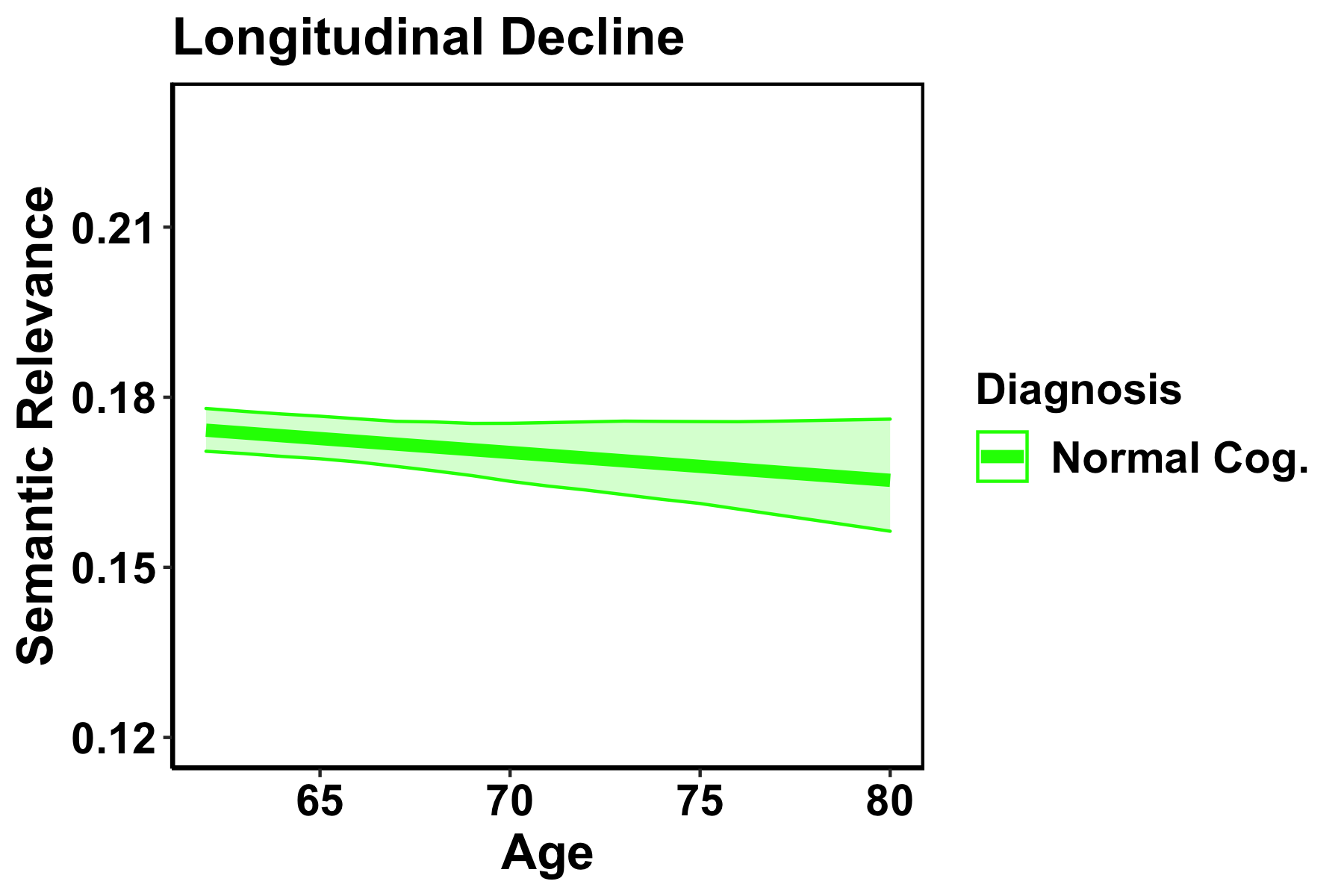 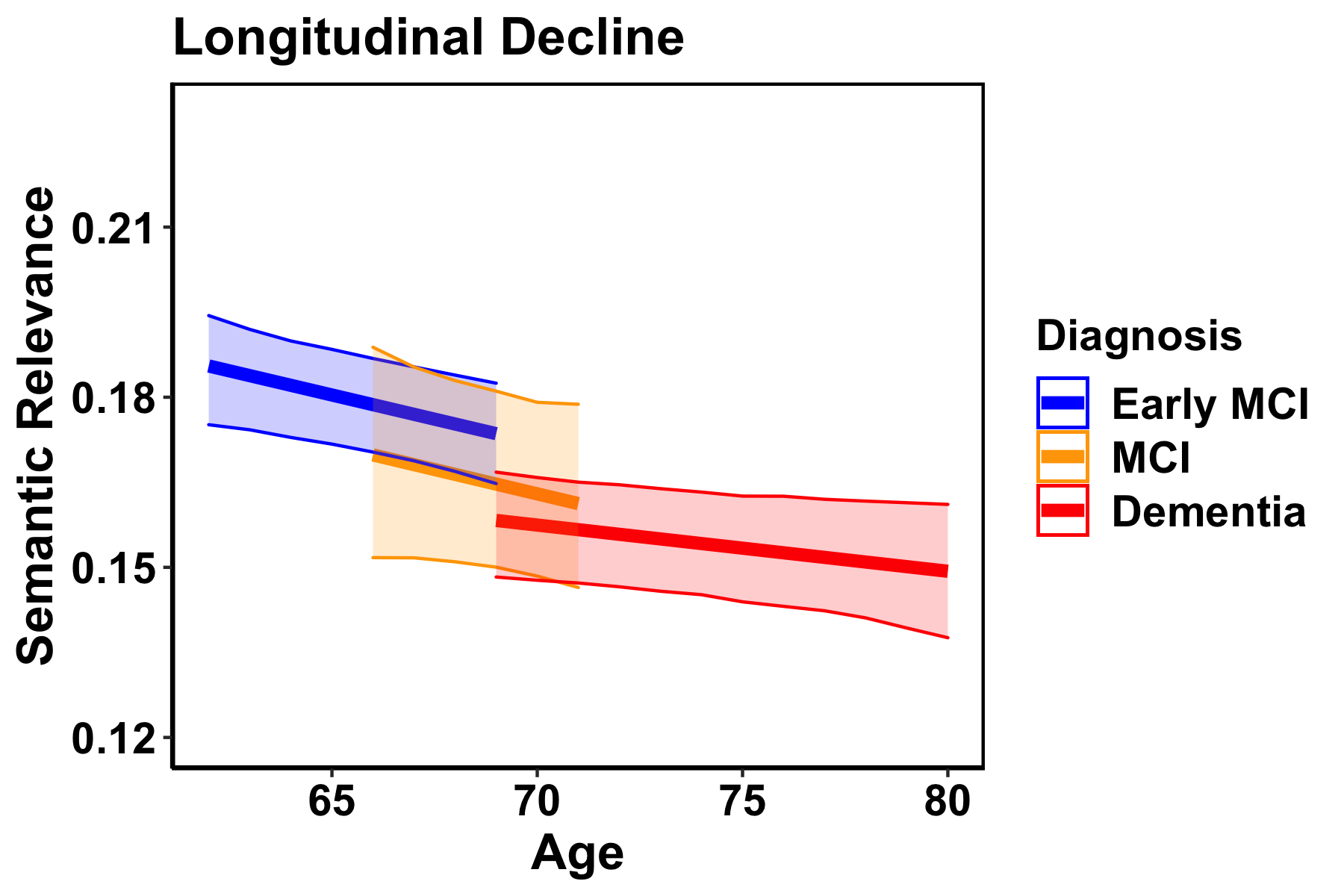 |
Taken together, these results demonstrate that semantic relevance is a clinically relevant language feature that is both cross-sectionally and longitudinally related to cognition. This is a significant finding because our automated measure is as valuable as the manually-coded version of semantic relevance, but doesn’t require time-consuming transcript coding. Like many hand-extracted lexico-semantic metrics, semantic relevance correlates strongly with the MMSE and declines with age and the severity of cognitive impairment. Results support the clinical use of this algorithm to automatically capture semantic unit idea density in the context of cognitive decline.
Digital speech-based measures separate those with cognitive impairment from those without
Our second study demonstrated that automatically-derived speech and language features can be used to determine whether a person is healthy or cognitively impaired. To show this, we fit a model to separate study participants with normal cognition from those with dementia. To avoid spurious correlations and overfitting, we used two key safeguards: first, models used a small set of meaningful speech measures that have been linked to cognitive impairment in previous studies. These included measures of vocabulary, use of pronouns, the content density of the speech, the complexity of speech, the complexity of the words used, the attention to detail and ability to accurately describe the picture, and a measure of thought agility. Second, we reported model fits using k-fold cross-validation. Our dementia model was able to separate the group with normal cognition from the group with dementia with ROC AUC = 0.91.
The ability to classify between healthy and cognitively impaired groups based on language use is a clear demonstration of the value of speech in assessment of cognitive impairment.
Comparison of Remote and In-Person Digital Speech-Based Measures of Cognition
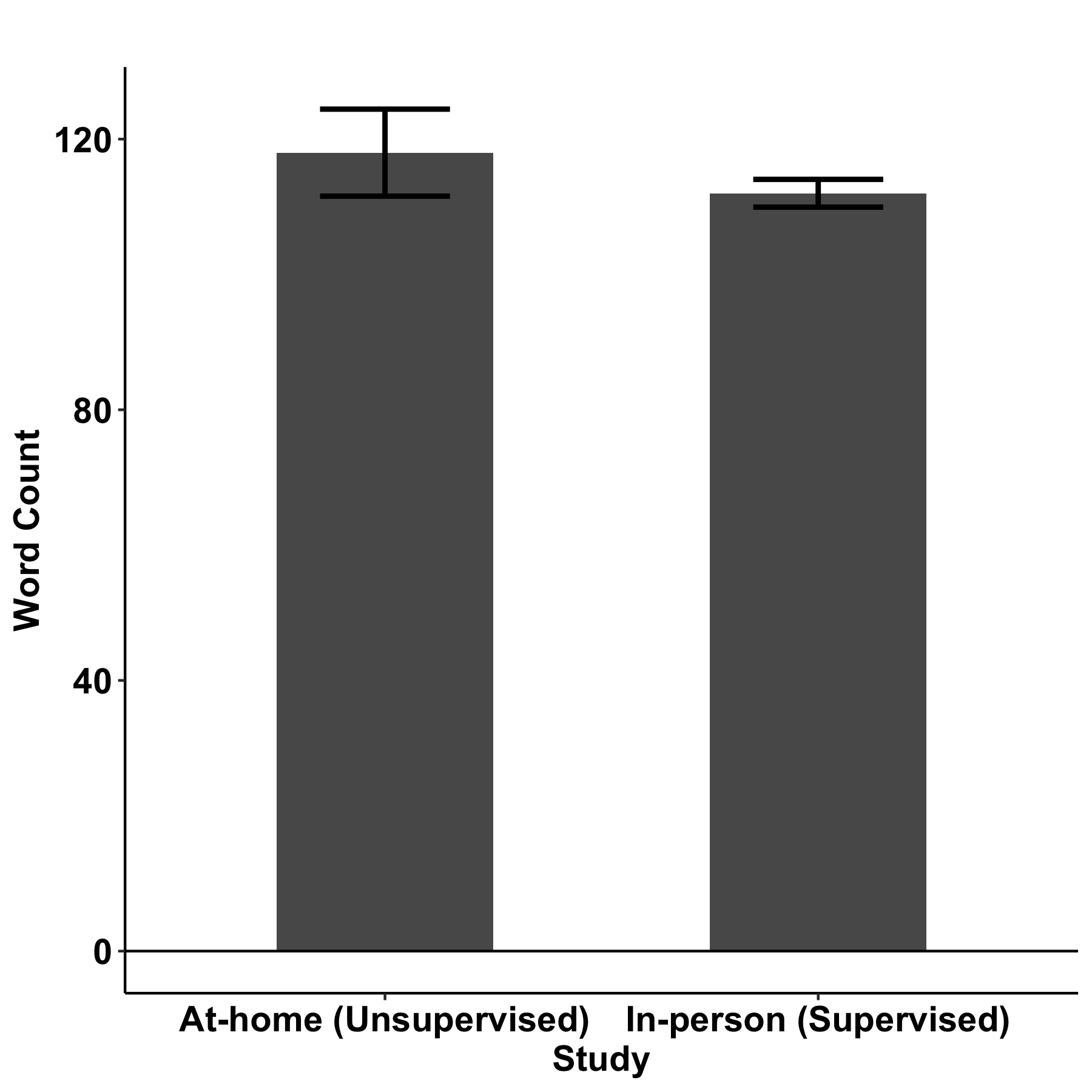
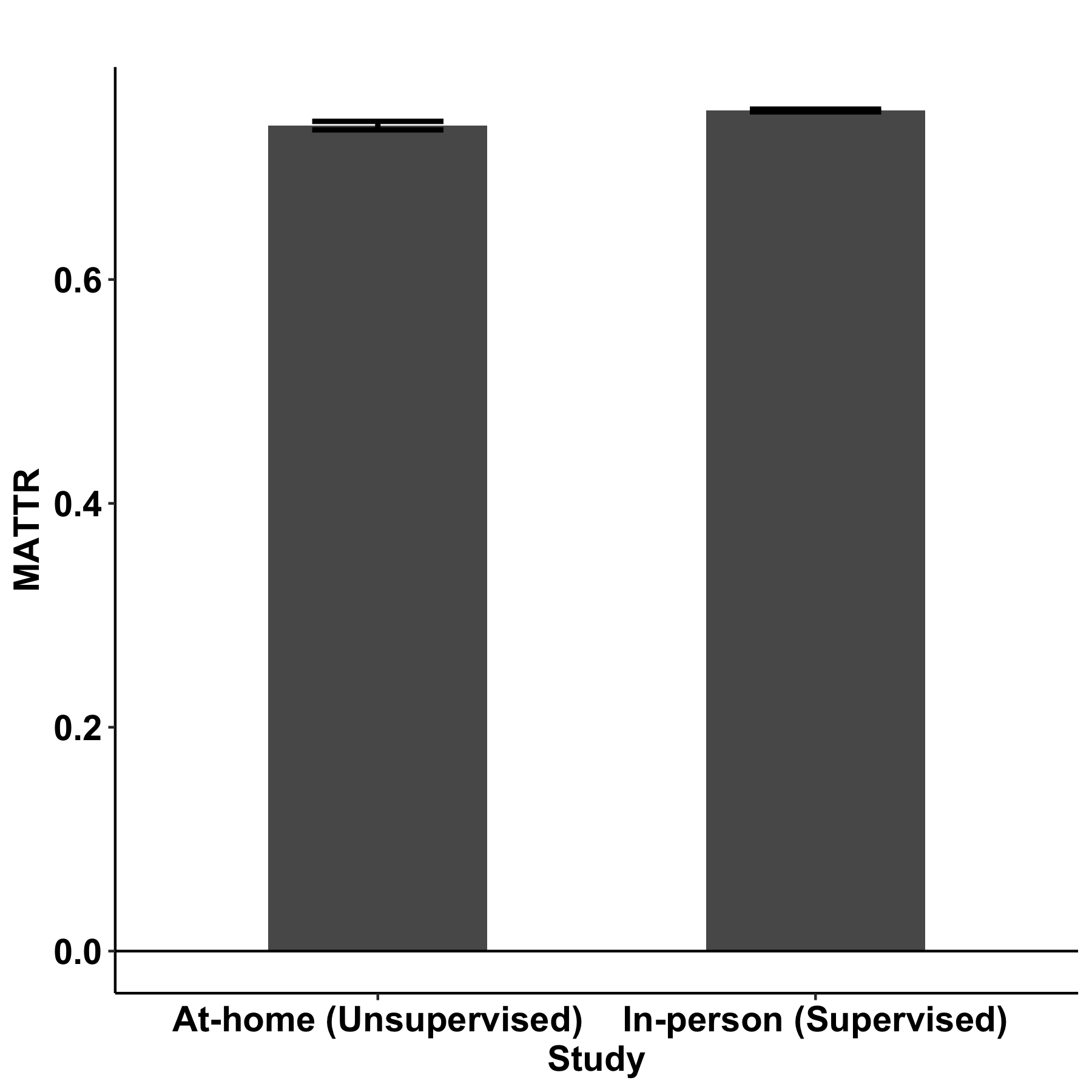
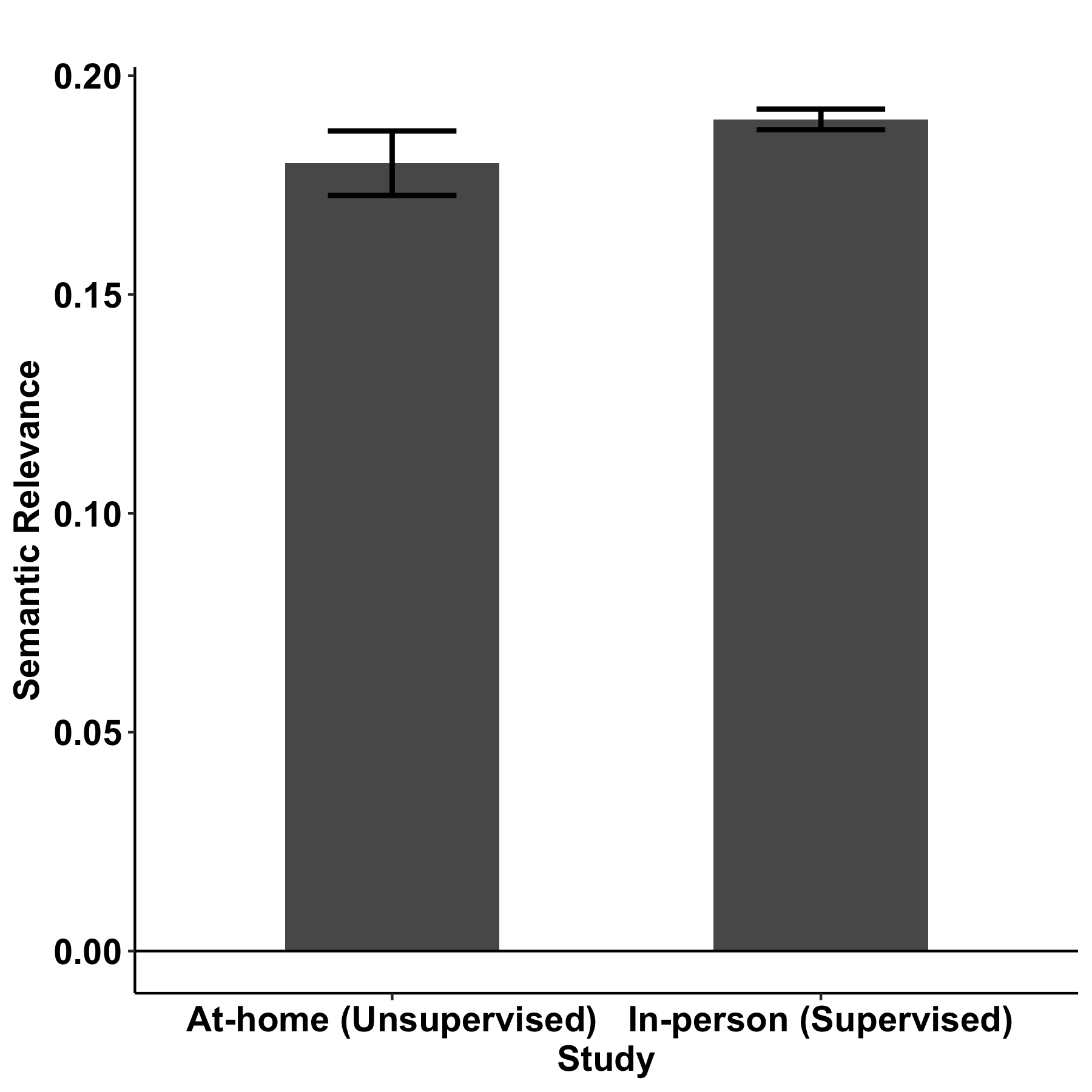
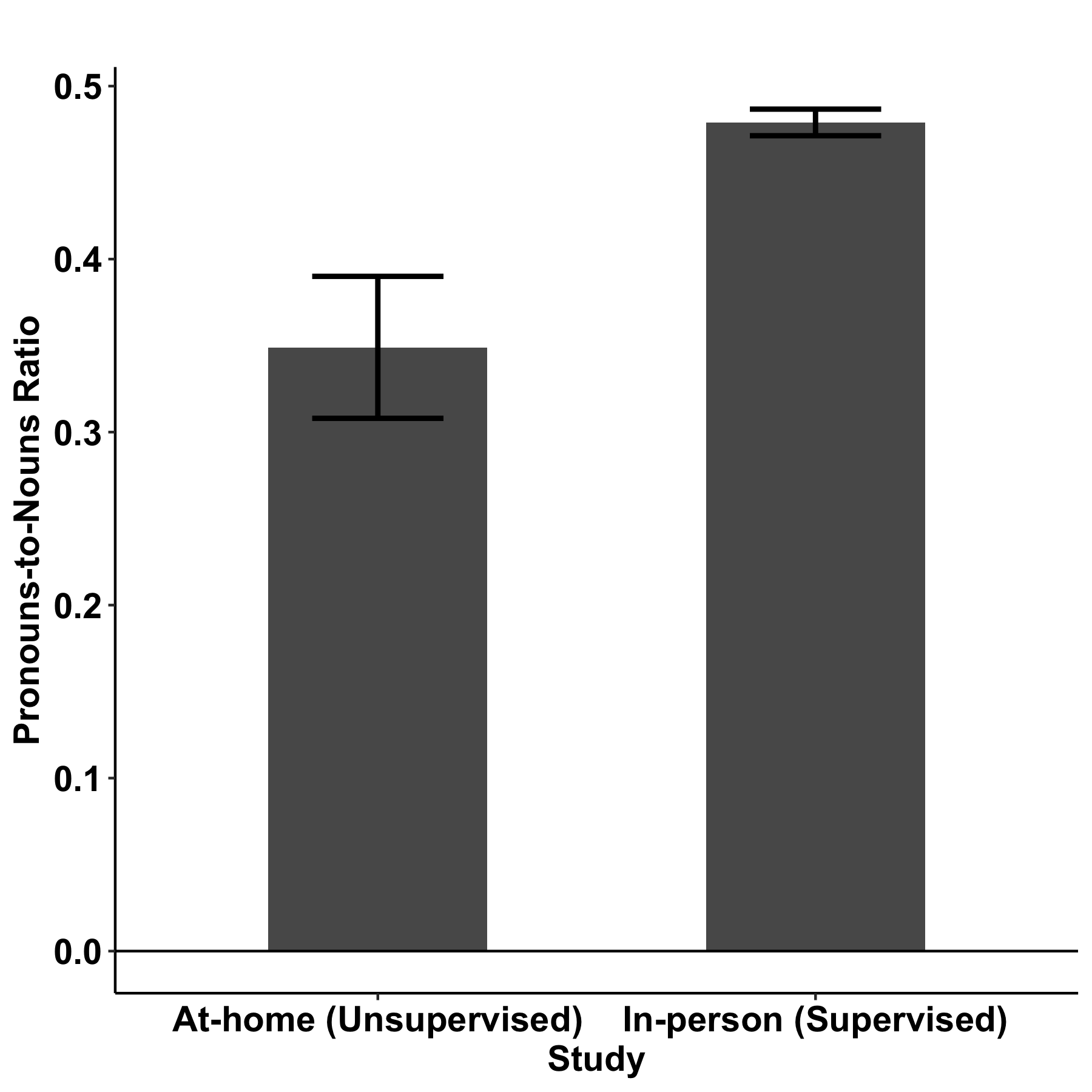
The two research contributions described above are bolstered by a third study that we presented. This third study demonstrated that speech elicitation tasks can be administered in an unsupervised, at-home environment without substantial impact on speech-based measures of cognition. To determine the impact of remote data collection, we set up two groups of healthy participants: (1) participants who provided picture descriptions in the usual way — in a clinical setting, supervised by a clinician — and (2) participants who provided picture descriptions at home via an app with no supervision. We automatically extracted language metrics from their recorded descriptions, and compared metrics collected in the supervised setting to metrics collected in the unsupervised, at-home setting. We focused on a small set of metrics known to be impacted by cognitive decline: measures of lexical access (MATTR), pronoun use (pronoun-to-noun ratio), volition (number of words), and general cognition (semantic relevance). Their descriptions were recorded and analyzed such that we extracted a small set of speech features of interest, including a measure of vocabulary, their use of pronouns, number of words, and the degree to which their speech related to the task of describing the picture.
We found that the word counts and the degree to which their speech related to the picture were not significantly different between the two settings, indicating a similar level of engagement and focus on the task. We found small differences in pronoun-to-noun ratio and MATTR between the two groups; follow-on studies to investigate these differences in healthy and cognitively impaired populations are in progress.
 |  |
 |  |


