As the pandemic forces healthcare and pharmaceutical clinical trials to adopt new modes of engaging with patients, the value of digital biomarkers and digital diagnostics is skyrocketing. Speech analytics, in particular, has received significant attention because of its ubiquitous nature, the ease and affordability of capturing speech on remote devices, and the rich information that can be gleaned about someone’s condition from the speech signal. But the unfortunate reality is that it’s easy to get out over your skis developing speech analytics for applications in clinical populations. This is because speech can be difficult to analyze: it is a large, complex signal, sampled tens of thousands of times per second. To tame this complexity, scientists and developers often turn to open-source software, which turns speech recordings into a bundle of hundreds to thousands of features based on characteristics of the signal. Although it’s tempting to unleash the power of AI on these vast feature sets–and many have done just that–the results of these models are rife with problems. This is because the features are not repeatable or interpretable (junk in) and the small sample sizes result in overfit, uninterpretable models that don’t generalize (junk out).
Recently, we published a paper in Digital Biomarkers that documents poor levels of repeatability for most of the speech features outputted from common open-source speech analytics platforms. This means that the speech features, objectively measured from recorded speech, are unacceptably variable from one day to the next. This variability makes it more difficult to see clinically important differences, and can raise the odds of being fooled by a statistically “lucky” study result. The data in our paper provides recommendations on how to mitigate the impact of using low-repeatability speech features in longitudinal studies and in machine learning algorithm development. But ultimately, it is the responsibility of those working to commercialize speech-based endpoints and of the scientific community to develop robust and interpretable fit-for-purpose speech features that meet clinical standards for endpoints.
Development starts with identifying where variability in speech features comes from. We find that much of the variability has 3 sources: the speech task that a person performs, the algorithms or measurements used to analyze recordings of those tasks, and variability in the clinical population.
Performance variability
The first source of variability comes from the way that participants perform the task. The fewer constraints the task has, the more variable the responses. A fully unconstrained task — think passive data collection, where your phone mic is on all day, or a recording of a conversation — is the most variable. A conversation with one’s boss differs in tone, content, and style from a conversation with a friend.
Constraints can have two functions. One is limiting the content of the recording or the way in which it is spoken. In a constrained task, say, reading a list of words in a soundproof booth, the experimenter has a good idea of what words will be said, the speaker’s intonation and rhythm, and how precisely they will speak (assuming that participants follow instructions). Constraints can also impose cognitive effort, or load, on the speaker, making it more difficult to complete the task. For a fluent reader and a sentence at an appropriate reading level, reading a sentence is a piece of cake. But tasks used in the neuropsychology world, like hearing a paragraph-length story and then repeating that story back verbatim — those tasks take effort. The graphic below shows how we think about task design.
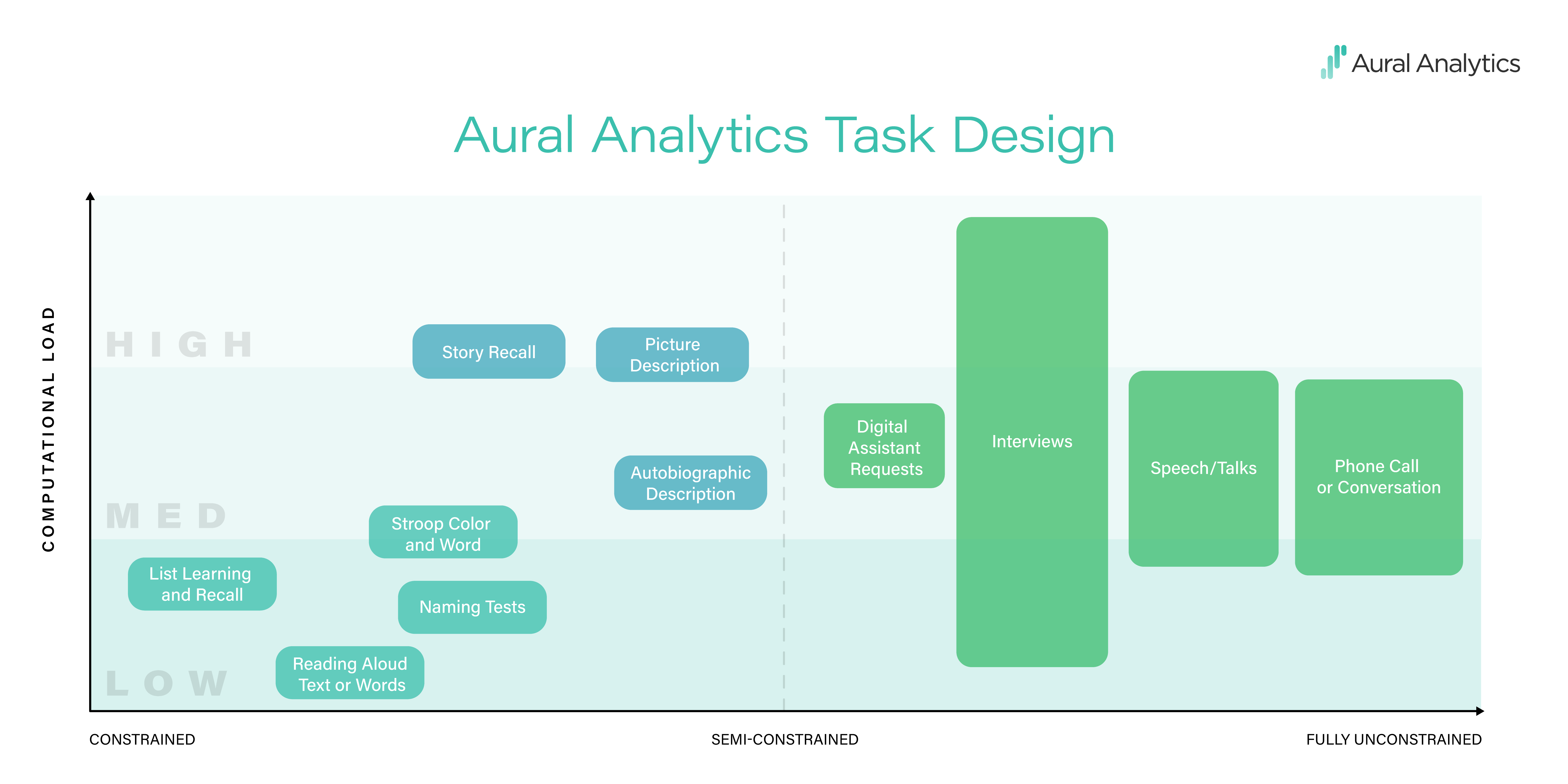
The design challenge when working with small clinical samples is to keep repeatability high while taxing the parts of the language system that are impacted by the disease. In the language of the graphic, we encourage repeatability by constraining task responses while varying cognitive load, making sure that tasks are hard in a way that matters for the population being studied.
Measurement error
The second source of variability is measurement error. Let’s consider a simple example, measuring how quickly someone reads a pre-specified paragraph, in words per minute. Getting this right requires correct measurement of the number of words and the number of minutes, and both are prone to error. You can’t assume you know the number of words in advance because the participant may have skipped or misread words in the paragraph they were given. And transcripts are subject to error, whether they are produced by a human or a speech recognition engine. Getting the number of minutes right is also hard. Stopwatch measurements are error-prone, automatic measurements can be fooled by background noise, and human annotations are subject to bias.
No matter what method is used, it’s important to quantify this error with respect to the best ground truth available: when combined with task performance variability, this is what determines the smallest change that would be observable in a study, and the sample size needed to observe that change.
Assessing clinical relevance
The linchpin of this whole fit-for-purpose process is the purpose. In clinical applications, the most accurate measurement using the most repeatable task is useless if it doesn’t provide information about the disease of interest.
A fit-for-purpose speech feature in clinical speech analytics should measure something that is known to be impacted by the disease, and should change with the disease while remaining fairly stable from day to day. To give a concrete example, let’s compare two speech features that could be used to track progression of amyotrophic lateral sclerosis (ALS): speaking rate and the Hammarberg Index. Speaking rate is a measurement of how quickly a person is speaking. The Hammarberg Index quantifies the loudness difference between high and low frequencies in the speech recording.
Speaking rate is a fit-for-purpose speech feature because the etiology of ALS gives us reason to believe that speaking rate should slow as bulbar symptoms secondary to ALS progress, and scientific literature supports this. We also know, from our own data collection in ALS, that speaking rate derived from read sentences has a reliability of 0.97 (on a scale from 0 to 1). This tells us that speaking rate is clinically relevant to ALS, and that the way we are measuring speaking rate is stable from day to day in the absence of disease progression.
On the other hand, the neuroscience of ALS does not make any predictions about whether or how the Hammarberg Index should change as the disease progresses. Furthermore, the Hammarberg Index, when extracted from the same set of read sentences, has a reliability of 0.63, which means that your Hammarberg Index can change from one day to the next for many reasons other than disease progression.
A path forward
The path to better speech endpoints isn’t easy, but the process is straightforward.
To choose what to measure, look to the disease’s etiology. If you are measuring Parkinson’s disease, talk to a neurologist or a speech language pathologist who works with dysarthria or review the decades of literature on the topic; then select a “short list” of features that are connected directly to the disease. This lets you reduce the number of features that you measure and check that the results make clinical sense. We like to call this hypothesis-driven feature selection.
To choose how to measure it, select a constrained task, and dial the cognitive load to the right level for the clinical population (take a look at our task graphic — cognitive load is on the y-axis, from low to high).
Finally, check your work! Take a few repeated measurements from the clinical group and some healthy controls. Make sure that the features correlate well with the aspect of the disease you’re trying to measure, and make sure that the features are repeatable.
Proponents of AI for clinical speech applications take a different approach. Rather than relying on a small number of clinical features, they use supervised learning on hundreds or thousands of features to develop predictive models that classify patients by disease or predict disease severity. At face value, this is appealing because the approach takes the clinician out of the loop and simply lets the data do the talking. But these models do not generalize well to new datasets. The reason, as we highlight in our Digital Biomarkers paper, is that variability in these high-dimensional feature sets combined with small sample sizes results in overfitting. To responsibly make use of data-driven approaches, the clinical speech community must develop more robust clinically-relevant features. These features and large clinical speech corpora will eventually have a profound impact on the field. But we are not yet ready to rely strictly on data-driven supervised learning models.
By working together as a community to validate our endpoints, we can do our part to head off the replication crisis that plagues not only clinical speech science, but the behavioral sciences more broadly.